No Model Selector, Always the Best Models
There are a lot of models these days. I find myself asking the same question – like literally the exact same prompt copy and pasted – to various models from various providers. I use the exact same prompt because I’m curious to probe how the various models behave. The improvements that are coming at an ever-increasing pace1 certainly drive this behavior. Who doesn’t want to use the latest model(s)? But what is becoming more evident, especially in those shrinking “stable” periods of time where no major updates have been released, is that the character of the models also drives this desire to test responses.
Character, that soft, squishy, subjective element, also introduces a kind of wild card factor to consumer preference. It’s not just “the correct model wins.” That’d be too easy. Character in an LLM may be something as important as the UI on any device or application, i.e. the deciding factor. We can joke about how the universal UI is the text box these days, but I think that may be missing the point that the experiential UI2 is the character of the model.
Even if you’re sticking to a single foundation model provider like OpenAI there’s still a variety of models to pick from (not to mention the hilariously unhelpful model names). So, this brings me to my main question today: will we, the end user, be picking models in the future?
With model picking in the air, comments from a recent interview3 on the topic of distinct model capabilities and “personalities” from Surge AI’s CEO, Edwin Chen, caught my interest.
I see a world where there actually will be multiple frontier AI companies, frontier AGIs, just because every one of them will be able to go in a different direction. Like you see it already, you see it today playing out already with the differences and the the strengths and weaknesses of OpenAI, Anthropic. And I just think that that trend will will continue.
The interviewer probes a little, asking for more detail and whether Edwin thinks there’ll be 10 more major foundation model companies:
I don’t know if there’ll be 10 more of them, but I can certainly see even like three more of them. And I just think each one will have different tradeoffs that they’re willing to make, different focuses that they’ll have. And like even today, like Claude is really really good at coding. Claude is really really good, I think, at enterprise and like instruction following whereas ChatGPT is yeah it’s like more optimized for consumer use cases like I think it actually has a really really great and fun personality right now and then Grok like yeah Grok is willing to maybe answer certain questions that maybe maybe it should maybe it shouldn’t but it’s willing to uh be a little bit transgressive in ways I actually think are very very interesting and so I actually think that um just like this willingness to have different personalities and different boundaries and different focuses on your models that that just leads um that leads the models to be good at different use cases. Just in the same way that like yeah there’s like I think analogy is there isn’t a single poet there isn’t a single mathematician that is like the the greatest mathematician of all time. They all have different focuses. They all have different ways of approaching these problems. And I think that richness of like what we often call like richness of human intelligence that will apply to to models as well.
The burgeoning differences in models and the fact that those differences are now becoming widely-recognized characteristics matches my experience. On the one hand it’s not too surprising, of course you can train/tune models to have specific characteristics or focuses. But on the other hand, with the AGI concept being a backdrop here, there is a certain expectation that if fundamental truth4 is a goal that there may be some room for personality differences but at some level the output of these models given identical inputs “should” be the “same”, right?
The day after I listened to that interview I came across Amp from Sourcegraph. I haven’t used it (yet), but it’s positioning itself as a flexible coding agent somewhere between Cursor and Claude Code – you can chose your own adventure as far as preferring an IDE or not, or Why not both?
I read their user manual to get an overview, and found the opening Principles pretty interesting (who doesn’t appreciate a good set of principles up front?), but principle #2 really stood out to me: No model selector, always the best models.

This brings me to an interesting question: will this work? How it may possibly work is also interesting, and certainly not easy, but whether or not Amp Code can stick to their principle guns on this point is something I look forward to checking in on.
If we’re really heading towards a world of differentiated foundational models with various strengths and weaknesses, I s’pose the claim here is that there’ll be ~one that is best fit for prompt interpretation or prompt preprocessing and Amp Code’s approach will be to maximize trust in their delegation process. As a matter of UX, it’s admirable and maybe even ideal. And perhaps the scope of coding will make this not too wild a goal. But it does seem deeply contingent on achieving very high trust without fault.
As for me, the lowly consumer, the unbundled model reality of today has me feeling like I’ve got my LLM equivalent of Netflix vs HBO vs Hulu going on, and I know I’m in good company. Poe is the only “bundled” offering I’m aware of and what I originally found somewhat confusing is finally making sense as the overhead of appropriate model selection seems like it’s only on an increasing path.
There’s also probably a strange game theory at play with the major providers: are they watching each other, sussing out the nuance, tone, personality in different models? Are they afraid to deviate in creative or new ways from now-established LLM character norms? Probably 5.
To come full circle to my meager desires and testing model responses, what I think I want, for now, is something like a Grand Synthesizer model that is tasked with merging multiple distinct, possibly identical or possibly entirely different sets of information, into a nice synthesis. I don’t want judgment of the information, just efficiently merged summaries that reduce duplication and emphasize differences.
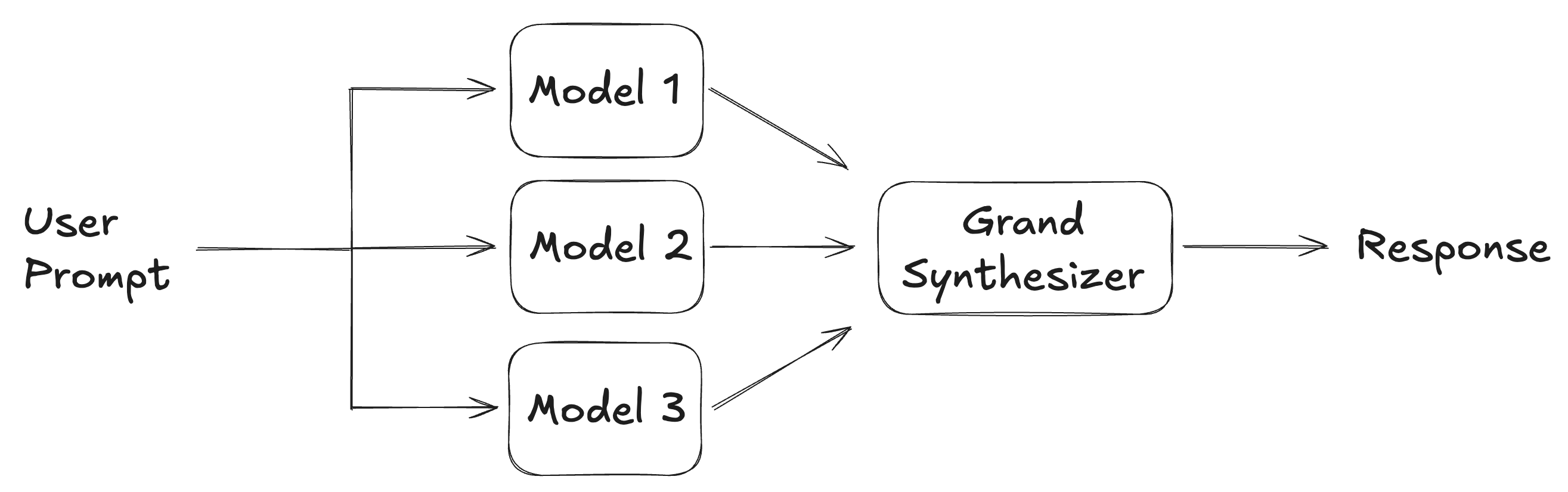
If I go a layer deeper and ask myself why I even have the desire for something like this, the answer is something like “I want to review the superset”. That’s not very deep, and conveys a desire to still participate, in a sense (I want to judge the answers). But I think it also conveys a sense that I haven’t settled on a strong personal preference. I suspect, for better or worse, that I’d pick the model I “like” and stick to it, should there ever be a winning personality.
-
I imagine the x-axis of a chart as time and the y-axis some hypothetical ‘overall awesomeness and efficacy’ scale that’s logarithmically approaching 100% with a decreasing interval in both steps up and time between steps such that we’ll enter an era of a smooth continuum of real-time incremental improvements. ↩︎
-
I’m making this term up as I go but it makes sense to me: we’re designing the medium (language) through which the experience is created. It’s a little different than the experience itself, which may vary significantly given the flexibility of this particular medium. ↩︎
-
Surge CEO & Co-Founder, Edwin Chen: Scaling to $1BN+ in Revenue with NO Funding, 20VC (youtube) ↩︎
-
Whatever the hell that is - but y’know what I’m trying to get at. ↩︎
-
Though it goes without saying if anyone is going to kool-aid man through a brick wall of propriety and try something out, it’s Elon and the xAI team with Grok. I imagine they’ll either hit on something great or take the punches to the face then course correct. ↩︎